

Hadoop Pros and Cons |Hadoop Limitations – Hadoop is an open-source framework widely used for processing and storing large datasets in a distributed computing environment. Developed by the Apache Software Foundation, Hadoop provides scalability, fault tolerance, and the ability to handle structured, semi-structured, and unstructured data. Its ecosystem includes tools like HDFS (Hadoop Distributed File System) for storage, MapReduce for processing, and YARN (Yet Another Resource Negotiator) for resource management.
Hadoop Pros and Cons |Hadoop Limitations

Hadoop revolutionized big data management by making it cost-effective to process massive amounts of data on commodity hardware. Despite its popularity and widespread adoption, Hadoop is not without its challenges. Its limitations, ranging from inefficiencies in certain scenarios to a steep learning curve, have prompted the exploration of alternatives and complementary tools. Below, we delve into these limitations in detail.
Advantages of Hadoop
Hadoop offers several advantages that make it a popular choice for organizations dealing with big data. Here are some of the key benefits:
- Cost-Effective:
- Hadoop is an open-source framework, which means it can be used without licensing fees. Organizations can run Hadoop on commodity hardware, significantly reducing the overall cost of storage and processing compared to traditional data warehousing solutions.
- Scalability:
- Hadoop is designed to scale out easily by adding more nodes to the cluster. It can handle increasing amounts of data simply by adding additional servers, allowing organizations to grow their data processing capabilities without major reconfigurations.
- Flexibility:
- Hadoop can process various types of data—structured, semi-structured, and unstructured—making it highly versatile. This flexibility allows organizations to store and analyze diverse data sources without the need for extensive data transformation.
- Speed:
- While traditional data processing solutions may struggle with large volumes of data, Hadoop’s distributed processing model allows for faster data analysis. By breaking down large datasets into smaller blocks and processing them simultaneously across the cluster, Hadoop can deliver results more quickly.
- Fault Tolerance:
- Hadoop is built with fault tolerance in mind. It automatically replicates data across multiple nodes in the cluster. If a node fails, Hadoop can continue processing using the replicated data, ensuring that there is no data loss and that operations can proceed smoothly.
- High Throughput:
- Hadoop’s design enables high throughput for large datasets. The ability to process vast amounts of data in parallel allows organizations to gain insights faster, making it suitable for batch processing and big data analytics.
- Minimum Network Traffic:
- Hadoop minimizes network traffic by moving the computation closer to where the data is stored. Instead of transferring large volumes of data across the network, the processing occurs on the nodes where the data resides, reducing bandwidth usage and enhancing performance.
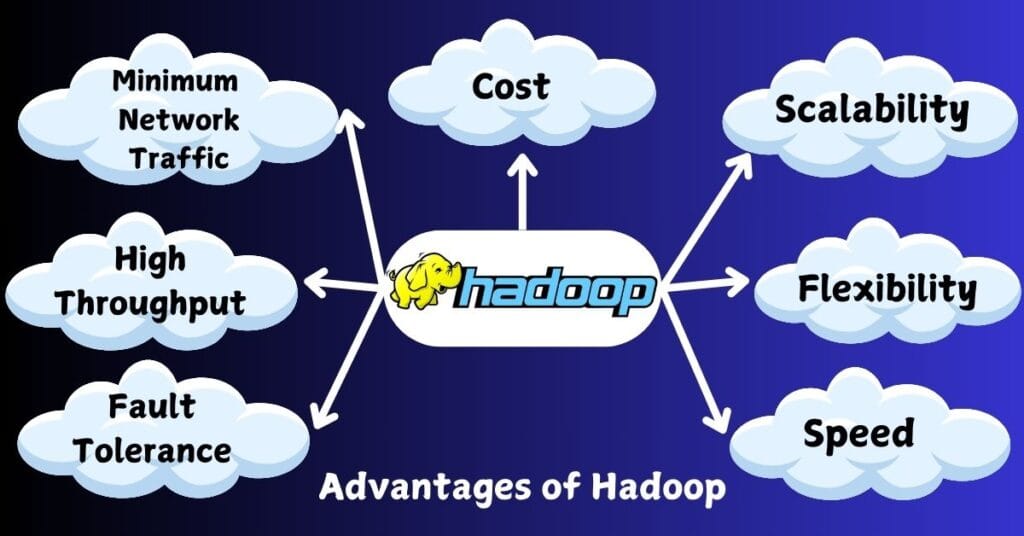
Hadoop’s combination of cost-effectiveness, scalability, flexibility, speed, fault tolerance, high throughput, and minimized network traffic makes it a powerful tool for organizations looking to leverage big data for insights and decision-making. Despite its limitations, these advantages contribute to its continued relevance in the big data landscape.
Disadvantages of Hadoop
Despite its many advantages, Hadoop also has several limitations that organizations should consider before adopting it for their big data solutions. Here are some of the key drawbacks:
- Problem with Small Files:
- Hadoop is not well-suited for handling a large number of small files. Each file stored in HDFS requires a separate metadata entry in the NameNode, which can lead to memory issues and decreased performance. This overhead becomes problematic as the number of small files increases.
- Vulnerability:
- Although Hadoop has made strides in improving security features, it still has vulnerabilities that can expose data to unauthorized access. Its security measures, such as Kerberos authentication, can be complex to implement, and many organizations may not fully leverage them, leading to potential data breaches.
- Low Performance in Small Data Surroundings:
- Hadoop’s performance is optimized for large datasets, making it inefficient for processing small data volumes. For use cases that involve small data processing, traditional databases or in-memory solutions may provide better performance.
- Lack of Security:
- Early versions of Hadoop had limited built-in security features, and while improvements have been made, it still lacks comprehensive security controls. Organizations may need to implement additional layers of security to protect sensitive data.
- High Upfront Processing Cost:
- Although Hadoop is cost-effective for large data volumes, the initial setup and resource allocation can be high. Organizations may need to invest significantly in infrastructure and resources to establish a functional Hadoop cluster, which can be a barrier for smaller businesses.
- Supports Only Batch Processing:
- Hadoop’s core processing model, MapReduce, is primarily designed for batch processing. This limitation makes it unsuitable for real-time data processing or interactive analytics, which are increasingly important for many modern applications. Organizations needing real-time capabilities may need to look for complementary technologies.
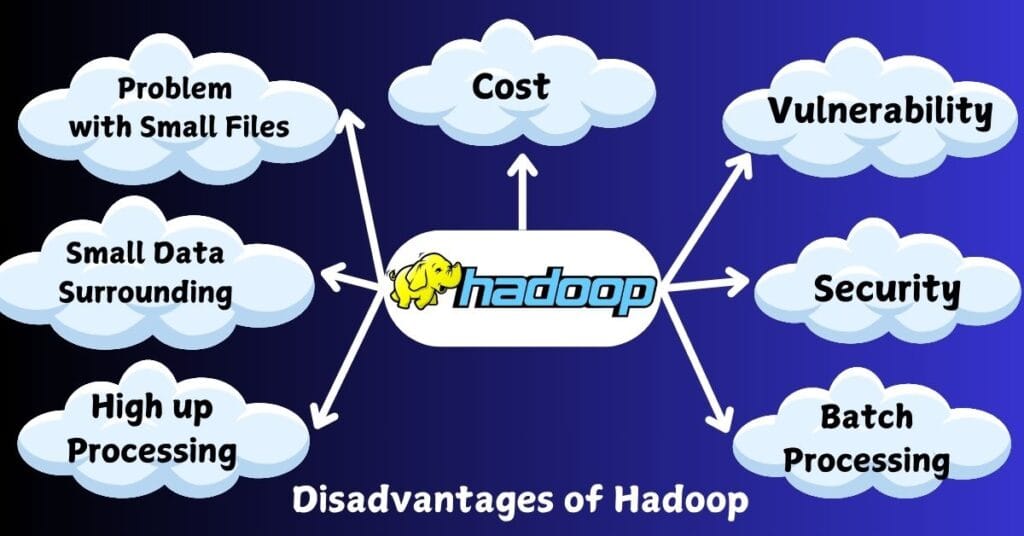
While Hadoop remains a powerful framework for big data processing, its limitations in handling small files, security vulnerabilities, low performance with small datasets, and exclusive focus on batch processing can hinder its effectiveness in certain scenarios. Organizations must carefully assess these disadvantages in relation to their specific data processing needs and consider alternative or complementary solutions when necessary.
Conclusion
Hadoop is a powerful framework for big data processing, offering advantages such as cost-effectiveness, scalability, flexibility, speed, fault tolerance, and high throughput. However, it also has significant limitations, including challenges with small files, security vulnerabilities, low performance with small datasets, high upfront processing costs, and a focus on batch processing.
Organizations must consider these drawbacks alongside the benefits when choosing Hadoop for their data processing needs. To maximize their data management capabilities, businesses should explore complementary technologies that address specific requirements, especially for real-time processing and enhanced security.
| For AR-VR Notes | Click Here |
| For Big Data Analytics (BDA) Notes | Click Here |